|
|
|||||||||
|
|
|||||||||
|
Title:
|
Dublin Core Abstract Model |
|
Creator:
|
Andy
Powell
UKOLN, University of Bath |
|
Date Issued:
|
2003-08-11
|
|
Identifier:
|
|
|
Replaces:
|
|
|
Is Replaced By:
|
Not applicable
|
|
Latest Version:
|
|
|
Status of Document:
|
This is a DCMI Working Draft.
|
| Description of Document: | This document describes an abstract model for Dublin Core metadata records. |
|
|
|
This document specifies an abstract model for Dublin Core (DC) metadata records [DCMI]. The primary purpose of this document is to provide a reference model against which particular DC encoding guidelines can be compared, in order to facilitate better mappings and translations between different syntaxes.
This document uses the following terms:
The abstract DC model for qualified DC metadata records is as follows:
The italicised terms used in this description are defined in the terminology section above.
Note that, in general, the value string should be a string that does not contain any markup.
It recognised that many real-world metadata applications will use additional properties beyond those indicated in the third bullet point above. While such usage does not fall strictly within the definition of 'qualified DC' provided here, such applications are strongly encouraged to conform to the DCMI abstract model in order to achieve maximum interoperability with other DC metadata records.
The abstract model for simple DC metadata records is a simplification of the qualified DC model defined above:
The process of translating a qualified DC metadata record into a simple DC metadata record is normally referred to as 'dumbing-down'. In terms of the abstract model, the dumb-down algorithm is as follows:
Note that software should make use of the DCMI term declarations represented in RDF schema language [DC-RDFS] and the DC XML namespaces [DC-NAMESPACES] to automate steps 4 and 5.
Particular encoding guidelines (HTML meta tags, XML, RDF/XML, etc.) [DCMI-ENCODINGS] do not need to encode all aspects of the abstract models described above. However, DCMI recommendations that provide encoding guidelines should refer to the models described this document and should indicate which parts of the models are encoded and which are not. In particular, encoding guidelines should indicate whether any rich values or related metadata records associated with a value are embedded within a DC record or are encoded separately and linked to it using a URI.
Thanks to Pete Johnston and the members of the DC Usage Board for their comments on previous versions of this document.
This appendix discusses 'structured values', as they are used in DC metadata applications at the time of writing.
Many existing applications of DC metadata have attempted to encode relatively complex descriptions (i.e. descriptions that contain more than simply a property and its string value). These attempts have been loosely referred to as 'structured values'. It is possible to identify a number of different kinds of structured values. Four are enumerated below. The first two of these are recommended by the DCMI, in the sense that there are a number of existing encoding schemes that define values that conform to these definitions of structured values. The latter two are not currently recommended, but it is likely that they are in fairly common usage across metadata applications worldwide.
These are value strings that contain explicitly labelled components within the string. Examples of this kind of structured value include:
<meta name="dcterms:temporal"
scheme="dcterms:Period"
content="start=Cambrian period; scheme=Geological timescale; name=Phanerozoic Eon;" />
<meta name="dc:creator"
content="BEGIN:VCARD\nORG:University of Oxford\nEND:VCARD\n" />
Note that vCard is not currently a DCMI recommended encoding scheme.
These are value strings that contain implicit components within the string, i.e. the components are determined based solely on their position within the string. Examples of this kind of structured value include:
<meta name="dc:date"
scheme="dcterms:W3CDTF"
content="2003-06-10" />
These are strings containing 'presentational' or other markup, for example adding paragraph breaks, superscripts or chemical/mathematical markup to a dc:description. It is possible to characterise various kinds of markup as follows:
These are metadata records that describe a second resource (i.e. not the resource being described by the DC record). For example, a related metadata record associated with a dc:creator property could contain a complete description of the resource author (including birthday, eye-colour and favourite beverage if desired!).
In the past, 'related resource descriptions' have tended to be encoded using XML, vCard (see above) or by inventing multiple 'refinements' of DCMES properties (for example DC.Creator.Address). The RDF/XML encoding of DC (see below) provides us with a more thorough modelling of related metadata records through the use of multiple linked nodes in an RDF graph.
In DC metadata records, the following elements (and their element refinements) are used to provide the name or identifier of a second resource that is related to the resource being described:
In the case of the first three, this is typically done by providing the name (or in some cases the name and a small amount of additional information in order to better identify the person or organisation) of the related resource as the value string.
In the case of the last two, this is typically done by providing the URI (or some other identifier) of the related resource as the value URI. However, where no identifier is available, the name of the related resource can be provided instead (or as well) using the value string.
It should be noted that the value strings of these elements (and their element refinements) are not intended to be used to provide full descriptions of the related resource.
The categories outlined above are not watertight and there are certainly overlaps between them. For example, labelled strings can be viewed as a type of non-XML markup language. In addition, there will be cases where marked-up text (e.g. MathML) can be viewed as a related resource description.
Nevertheless, the purpose of the categorisation used here is to try and analyse existing usage of complex metadata structures within current DC metadata applications. In the context of the abstract model proposed here, all the types of structured values outlined above form part of the qualified DC model:
This appendix discusses the relationship between the DC abstract model and the Resource Description Framework (RDF).
RDF currently provides DCMI with the richest encoding environment of the available encoding syntaxes. It is therefore worth taking a brief look at how the abstract model described here compares with the RDF model.
Note that the intention here is not to provide a full and detailed description of how to encode DC metadata records in RDF. Instead, three simple examples of the use of DC in RDF are considered.
|
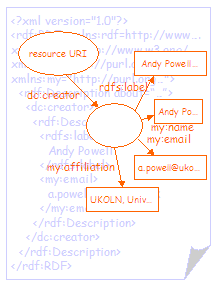
Figure 1 shows a simple RDF graph (and the RDF/XML document that represents it). The graph shows a resource with a single property (dc:creator). The value of the property is a second (blank) node, representing the creator of the resource. This second blank node has several properties, used to describe the creator, and an rdfs:label property that is used to provide the value string for the dc:creator property. |
|
|
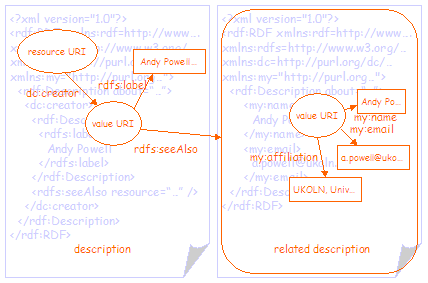
Figure 2 shows the same information separated into two graphs. In this case the related metadata that describes the creator has been more clearly separated from the description of the resource by moving it into a separate RDF/XML document. In order to do this, the node representing the value has been assigned a value URI, allowing the two nodes in the two RDF/XML documents to be treated as representing the same thing. The related metadata in the second RDF/XML document is linked to the first using the rdfs:seeAlso property and the URI of the RDF/XML document. Note that it is not strictly necessary to separate the two graphs in this way; it is perfectly valid to represent the second graph as a sub-graph of the first, as shown in figure 1. However, for the purposes of this document, the two graphs have been separated in order to more clearly differentiate the DC metadata record from the related metadata. In some cases it will be good practice to facilitate this separation anyway. For example, in order to serve the second graph from a directory service of some kind. |
|
|
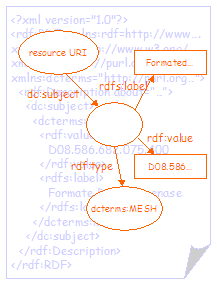
Figure 3 shows a second simple RDF graph (and the RDF/XML document that represents it). The graph shows a resource with a single property (dc:subject). The value of the property is a second (blank) node, representing the subject of the resource. This second blank node has an rdfs:label property that is used to provide the value string for the dc:subject property, an rdf:value property that is used to provide the classification scheme notation and an rdf:type property to provide the encoding scheme URI. |
|
|
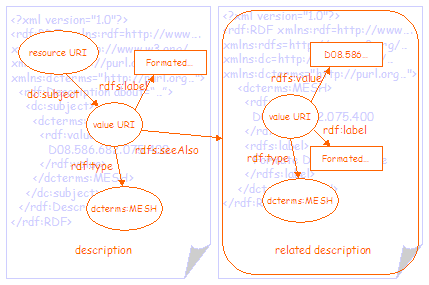
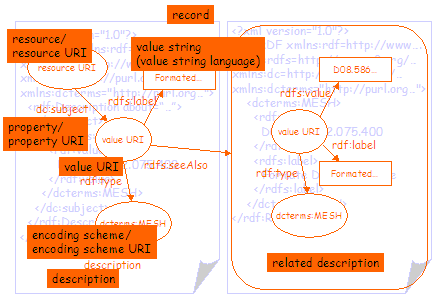
Figure 4 shows the same information separated into two graphs. In this case the related metadata that describes the subject has been more clearly separated from the description of the resource by moving it into a separate RDF/XML document. In order to do this, the node representing the value has been assigned a value URI, allowing the two nodes in the two RDF/XML documents to be treated as representing the same thing. The related metadata in the second RDF/XML document is linked to the first using the rdfs:seeAlso property and the URI of the RDF/XML document. Note that it is not strictly necessary to separate the two graphs in this way; it is perfectly valid to represent the second graph as a sub-graph of the first, as shown in figure 3. However, for the purposes of this document, the two graphs have been separated in order to more clearly differentiate the DC metadata record from the related metadata. In some cases it will be good practice to facilitate this separation anyway. For example, in order to serve the second graph from a terminology service of some kind. |
|
|
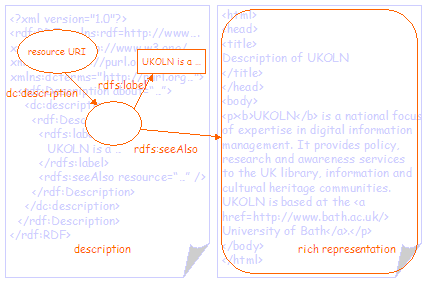
Figure 5 shows a third simple RDF graph (and the RDF/XML document that represents it). The graph shows a resource with a single property (dc:description). The value of the property is a second (blank) node with an rdfs:label property that is used to provide the value string for the dc:description property. The second node also has an rdfs:seeAlso property that links to a rich value - in this case some HTML marked-up text that provides a richer representation of the description. Note that it is possible to embed the marked-up text within a single RDF graph (using rdf:parseType="Literal"). However, this is not shown here. |
|
|
By re-visiting the second figure from example 2 (figure 4) it is possible to layer the terminology used in the abstract models above over the RDF graph. A similar exercise could be undertaken for other encoding syntaxes (e.g. XML and HTML meta tags). As mentioned above, it may be the case that the full richness of the abstract model is not able to be offered in all encoding syntaxes. |
|
![]()
![]()