|
|
|||||||||
|
|
|||||||||
|
Title:
|
DCMI Abstract Model |
|
Creator:
|
Andy
Powell
UKOLN, University of Bath, UK Mikael Nilsson KMR Group, CID, NADA, KTH (Royal Institute of Technology), Sweden Ambjörn Naeve KMR Group, CID, NADA, KTH (Royal Institute of Technology), Sweden Pete Johnston UKOLN, University of Bath, UK |
|
Date Issued:
|
2004-11-24
|
|
Identifier:
|
|
|
Replaces:
|
|
|
Is Replaced By:
|
Not applicable
|
|
Latest Version:
|
|
|
Status of Document:
|
This is a DCMI Working Draft.
|
| Description of Document: | This document describes an abstract model for DCMI metadata descriptions. |
|
|
|
1.
Introduction
2.
DCMI abstract models
3.
Descriptions, description sets and records
4.
Values
5.
Dumb-down
6.
Encoding guidelines
7.
Terminology
References
Acknowledgements
Appendix A - A note about structured values
Appendix B - The abstract model and RDF
Appendix C - The abstract model and XML
Appendix D - The abstract model and XHTML
This document specifies an abstract model for DCMI metadata descriptions [DCMI]. The primary purpose of this document is to provide a reference model against which particular DC encoding guidelines can be compared. To function well, a reference model needs to be independent of any particular encoding syntax. Such a reference model allows us to gain a better understanding of the kinds of descriptions that we are trying to encode and facilitates the development of better mappings and translations between different syntaxes.
The abstract model of the resources being described by DCMI metadata descriptions is as follows:
The abstract model of DCMI metadata descriptions is as follows:
The italicised terms used above are defined in the terminology section below. A number of things about the model are worth noting:
The DCMI abstract models for resources and descriptions are represented as UML class diagrams [UML] in figures 1 and 2.
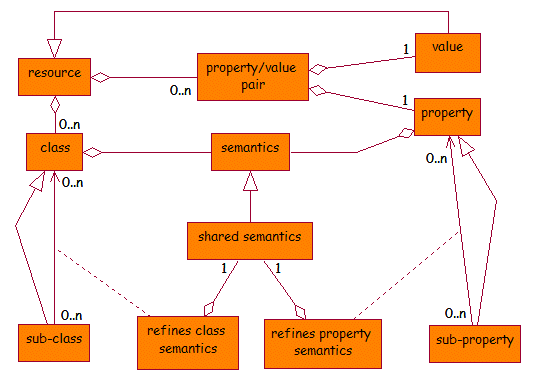
Figure 1 - the DCMI resource model
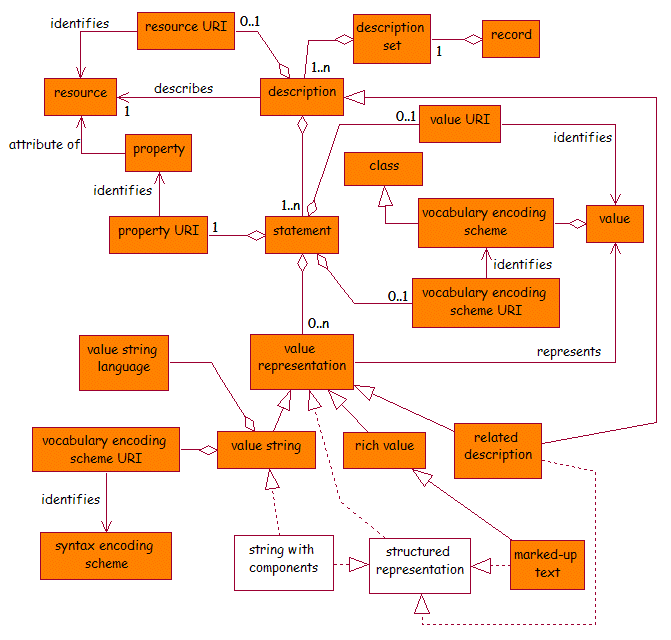
Figure 2 - the DCMI description model
Readers that are not familiar with UML class diagrams should note that lines ending in a block-arrow should be read as 'is' or 'is a' (for example, 'a vocabulary encoding scheme is a class') and that lines starting with a block-diamond should be read as 'contains a' or 'has a' (for example, 'a statement contains a property URI'). Other relationships are labelled appropriately. The classes represented by the clear boxes are not mentioned explicitly in the textual description of the abstract model above but are discussed in Appendix A. Note that the UML modelling used here shows the abstract model but is not intended to form a suitable basis for the development of DCMI software applications.
The abstract model described above indicates that each DCMI metadata description describes one, and only one, resource. This is commonly referred to as the 1:1 principle.
However, real-world metadata applications tend to be based on loosely grouped sets of descriptions (where the described resources are typically related in some way), known here as description sets. For example, a description set might comprise descriptions of both a painting and the artist. Furthermore, it is often the case that a description set will also contain a description about the description set itself (sometimes refered to as 'admin metadata' or 'meta-metadata').
Description sets are instantiated, for the purposes of exchange between software applications, in the form of metadata records, according to one of the DCMI encoding guidelines (XHTML meta tags, XML, RDF/XML, etc.) [DCMI-ENCODINGS].
This document defines a description set and a DCMI metadata record as follows:
A DCMI metadata value is the physical or conceptual entity that is associated with a property when it is used to describe a resource. For example, the value of the DC Creator property is a person, organisation or service - a physical entitiy. The value of the DC Date property is a point in time - a conceptual entity. The value of the DC Coverage property may be a geographic region or country - a physical entity. The value of the DC Subject property may be a concept - a conceptual entity - or a physical object or person - a physical entity. Each of these entities is a resource.
The value may be identified using a value URI; the value may be represented by one or more value strings and/or rich values; the value may have some related descriptions - but the value is a resource.
The notions of simple DC and qualified DC are widely used within DCMI documentation and discussion fora. This document does not present a definitive view of what these terms mean because their usage is somewhat variable. However, in general terms, the phrase 'simple DC' is used to refer to DC metadata that does not make any use of encoding schemes and element refinements while the phrase 'qualified DC' is used to refer to metadata that makes use of all the features of the abstract model described here.
The process of translating qualified DC into simple DC is normally referred to as 'dumbing-down'. The process of dumbing-down can be separated into two parts: property dumb-down and value dumb-down. Furthermore, each of these processes can be be approached in one of two ways. Informed dumb-down takes place where the software performing the dumb-down algorithm has knowledge built into it about the property relationships and values being used within a specific DCMI metadata application. Uninformed dumb-down takes place where the software performing the dumb-down algorithm has no prior knowledge about the properties and values being used.
Based on this analysis, it is possible to outline a 'dumb-down algorithm' matrix, shown below:
| Element dumb-down | Value dumb-down | |
| Uninformed | Discard any statement in which the property URI identifies a property that isn't in the Dublin Core Metadata Element Set [DCMES]. | Use value URI (if present) or value string as new value string. Discard any related descriptions and rich values. Discard any encoding scheme URIs. |
| Informed | Recursively resolve sub-property relationships until a recognised property is reached and substitute the property URI of that property for the existing property URI in the statement. If no recognised property is reached, then discard the statement. (In many cases, this process stops when a property is reached that is not an element refinement.) | Use knowledge of any rich values, related descriptions or the value string to create a new value string. |
Note that software should make use of the DCMI term declarations represented in RDF schema language [DC-RDFS] and the DC XML namespaces [DC-NAMESPACES] to automate the resolution of sub-property relationships.
In cases where software is dumbing-down a description set containing multiple descriptions, it may either generate several 'simpler' descriptions (one per description in the original description set) or a single 'simple' description (in which case it will have to determine which is the 'primary' description in the original description set). This is an application-specific decision.
Particular encoding guidelines (HTML meta tags, XML, RDF/XML, etc.) [DCMI-ENCODINGS] do not need to encode all aspects of the abstract model described above. However, DCMI recommendations that provide encoding guidelines should refer to the DCMI abstract model and indicate which parts of the model are encoded and which are not. In particular, encoding guidelines should indicate the mechanism by which resource URIs and value URIs are encoded. Note that the abstract model does not indicate that the combination of a DCTERMS URI syntax encoding scheme with a value string implies a value URI or resource URI. Encoding guidelines should provide an explicit mechanism for encoding these features of the model. Encoding guidelines should also indicate whether any rich values or related descriptions associated with a statement are embedded within the record or are encoded in a separate record and linked to it using a URI.
Appendices B, C and D below provide a summary comparison between the abstract model and the RDF/XML, XML and XHTML encoding guidelines.
This document uses the following terms:
Thanks to Tom Baker, the members of the DC Usage Board and the members of the DC Architecture Working Group for their comments on previous versions of this document.
This appendix discusses 'structured values', as they are used in DC metadata applications at the time of writing.
Many existing applications of DC metadata have attempted to encode relatively complex descriptions (i.e. descriptions that contain more than simply a property and its string value). These attempts have been loosely referred to as 'structured values'. It is possible to identify a number of different kinds of structured values. Four are enumerated below. The first two of these are recommended by the DCMI, in the sense that there are a number of existing encoding schemes that define values that conform to these definitions of structured values. The latter two are not currently recommended, but it is likely that they are in fairly common usage across metadata applications worldwide.
These are strings that contain explicitly labelled components. Examples of this kind of structured value include:
<meta name="dcterms:temporal"
scheme="dcterms:Period"
content="start=Cambrian period; scheme=Geological timescale; name=Phanerozoic Eon;" />
<meta name="dc:creator"
content="BEGIN:VCARD\nORG:University of Oxford\nEND:VCARD\n" />
Note that vCard is not currently a DCMI recommended encoding scheme.
These are strings that contain implicit components within the string, i.e. the components are determined based solely on their position within the string. Examples of this kind of structured value include:
<meta name="dc:date"
scheme="dcterms:W3CDTF"
content="2003-06-10" />
These are strings containing 'presentational' or other markup, for example adding paragraph breaks, superscripts or chemical/mathematical markup to a dc:description. It is possible to characterise various kinds of markup as follows:
These are metadata descriptions that describe a second resource (i.e. not the resource being described by the DC description). For example, a related description associated with the value of dc:creator could contain a complete description of the resource author (including birthday, eye-colour and favourite beverage if desired!).
In the past, 'related resource descriptions' have tended to be encoded using XML, vCard (see above) or by inventing multiple 'refinements' of DCMES properties (for example DC.Creator.Address). The RDF/XML encoding of DC (see below) provides us with a more thorough modelling of related metadata records through the use of multiple linked nodes in an RDF graph.
In DC metadata records, the following properties (and their element refinements) are used to provide the name or identifier of a second resource that is related to the resource being described:
In the case of the first three, this is typically done by providing the name (or in some cases the name and a small amount of additional information in order to better identify the person or organisation) of the related resource as the value string.
In the case of the last two, this is typically done by providing the URI reference (or some other identifier) of the related resource as the value URI. However, where no identifier is available, the name of the related resource can be provided instead (or as well) using the value string.
It should be noted that the value strings of these properties (and their element refinements) are not intended to be used to provide full descriptions of the related resource.
The categories outlined above are not watertight and there are certainly overlaps between them. For example, labelled strings can be viewed as a type of non-XML markup language. In addition, there will be cases where marked-up text (e.g. MathML) can be viewed as a related resource description.
Nevertheless, the purpose of the categorisation used here is to try and analyse existing usage of complex metadata structures within current DC metadata applications. In the context of the abstract model proposed here, all the types of structured values outlined above form part of the DCMI abstract model:
This appendix discusses the relationship between the DCMI abstract model and the Resource Description Framework (RDF).
RDF currently provides DCMI with the richest encoding environment of the available encoding syntaxes. It is therefore worth taking a brief look at how the abstract model described here compares with the RDF model.
Note that the intention here is not to provide a full and detailed description of how to encode DC metadata records in RDF. Instead, three simple examples of the use of DC in RDF are considered.
|
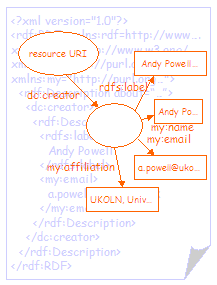
Figure 3 shows a simple RDF graph (and the RDF/XML document that represents it). The graph shows a resource with a single property (dc:creator). The value of the property is a second (blank) node, representing the creator of the resource. This second blank node has several properties, used to describe the creator, and an rdfs:label property that is used to provide the value string for the dc:creator property. |
|
|
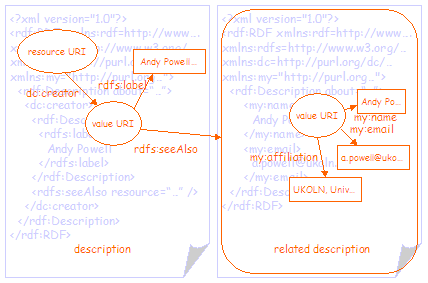
Figure 4 shows the same information separated into two graphs. In this case the related description that describes the creator has been more clearly separated from the description of the resource by moving it into a separate RDF/XML document. In order to do this, the node representing the value has been assigned a value URI, allowing the two nodes in the two RDF/XML documents to be treated as representing the same thing. The related description in the second RDF/XML document is linked to the first using the rdfs:seeAlso property and the URI of the RDF/XML document. Note that it is not strictly necessary to separate the two graphs in this way; it is perfectly valid to represent the second graph as a sub-graph of the first, as shown in figure 3. However, for the purposes of this document, the two graphs have been separated in order to more clearly differentiate the description from the related description. In some cases it will be good practice to facilitate this separation anyway. For example, in order to serve the second graph from a directory service of some kind. |
|
|
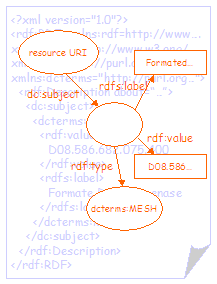
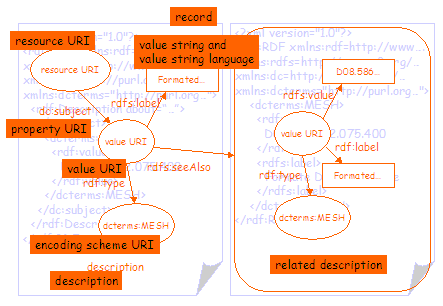
Figure 5 shows a second simple RDF graph (and the RDF/XML document that represents it). The graph shows a resource with a single property (dc:subject). The value of the property is a second (blank) node, representing the subject of the resource. This second blank node has an rdfs:label property that is used to provide the value string for the dc:subject property, an rdf:value property that is used to provide the classification scheme notation and an rdf:type property to provide the encoding scheme URI. |
|
|
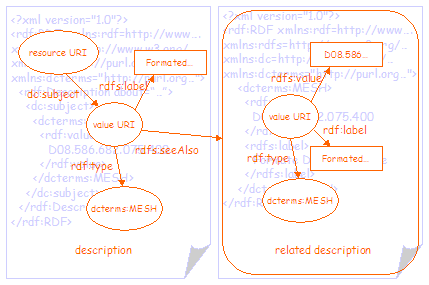
Figure 6 shows the same information separated into two graphs. In this case the related description that describes the subject has been more clearly separated from the description of the resource by moving it into a separate RDF/XML document. In order to do this, the node representing the value has been assigned a value URI, allowing the two nodes in the two RDF/XML documents to be treated as representing the same thing. The related description in the second RDF/XML document is linked to the first using the rdfs:seeAlso property and the URI of the RDF/XML document. Note that it is not strictly necessary to separate the two graphs in this way; it is perfectly valid to represent the second graph as a sub-graph of the first, as shown in figure 5. However, for the purposes of this document, the two graphs have been separated in order to more clearly differentiate the description from the related description. In some cases it will be good practice to facilitate this separation anyway. For example, in order to serve the second graph from a terminology service of some kind. |
|
|
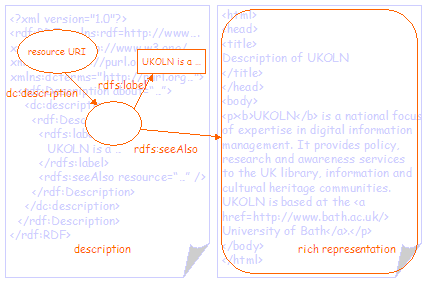
Figure 7 shows a third simple RDF graph (and the RDF/XML document that represents it). The graph shows a resource with a single property (dc:description). The value of the property is a second (blank) node with an rdfs:label property that is used to provide the value string for the dc:description property. The second node also has an rdfs:seeAlso property that links to a rich value - in this case some HTML marked-up text that provides a richer representation of the description. Note that it is possible to embed the marked-up text within a single RDF graph (using rdf:parseType="Literal"). However, this is not shown here. |
|
|
By re-visiting the second figure from example 2 (figure 6) it is possible to layer the terminology used in the abstract models above over the RDF graph. All aspects of the DCMI abstract model are supported by the RDF encoding guidelines. |
|
This appendix compares the DCMI abstract model with the Guidelines for implementing Dublin Core in XML DCMI recommendation.

Figure 9
Figure 9 shows an example simple DC description encoded according to the XML guidelines above. The example shows how the encoding supports the property URI, value string and value string language aspects of the DCMI abstract model. It should be noted that all the values that are encoded in this syntax are represented by value strings, even those that look, to the human reader, as though they are URIs.

Figure 10
Figure 10 shows an example qualified DC description encoded according to the XML guidelines above. This example shows how the encoding supports the property URI, value string, value string language, encoding scheme URI and resource class aspects of the DCMI abstract model. Note also that, although the resource class is indicated, the class URI is not encoded anywhere in this description.
The following aspects of the DCMI abstract model are supported by the Guidelines for implementing Dublin Core in XML recommendation:
The following aspects of the DCMI abstract model are not supported:
The following constraints apply:
Note that, at the time of writing, neither resource URIs nor value URIs can be explicitly encoded in the XML encoding syntax. Although it may be the case that some software applications have chosen to interpret the use of a DCTERMS URI syntax encoding scheme as an indication that the URI in the value string is a resource URI or value URI, this is not guaranteed to be a correct interpretation of the metadata record in all cases.
This appendix compares the DCMI abstract model with the Expressing Dublin Core in HTML/XHTML meta and link elements DCMI recommendation.

Figure 11
Figure 11 shows an example simple DC description encoded according to the XHTML guidelines above. This example shows how the encoding supports the property URI, value string, value string language and value URI aspects of the DCMI abstract model. Again, it should be noted that the value of the DC Identifier property represented in this encoding syntax is denoted by a value string, even though it looks, to the human reader, as though it is a URI.
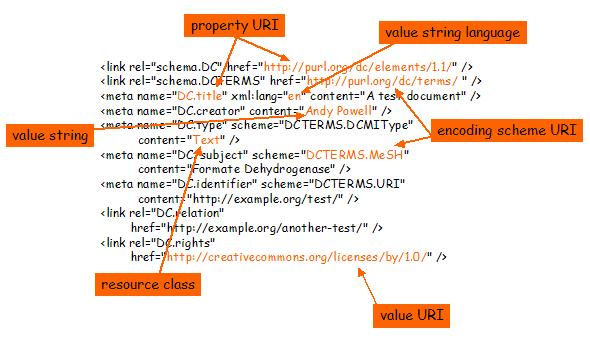
Figure 12
Figure 12 shows an example qualified DC description encoded according to the XHTML guidelines above. This example shows how the encoding supports the property URI, value string, value string language, value URI, encoding scheme URI and resource class aspects of the DCMI abstract model. Note that although the resource class is indicated, the class URI is not encoded anywhere in this description.
The following aspects of the DCMI abstract model are supported by the Expressing Dublin Core in HTML/XHTML meta and link elements DCMI recommendation:
The following aspects of the DCMI abstract model are not supported:
The following constraints apply:
Note that, at the time of writing, resource URIs cannot be explicitly encoded in the XHTML encoding syntax. However, the resource URI may be implicit from the URI of the resource into which the record is embedded.
![]()
![]()